alluvial diagram 冲积图
文章目录
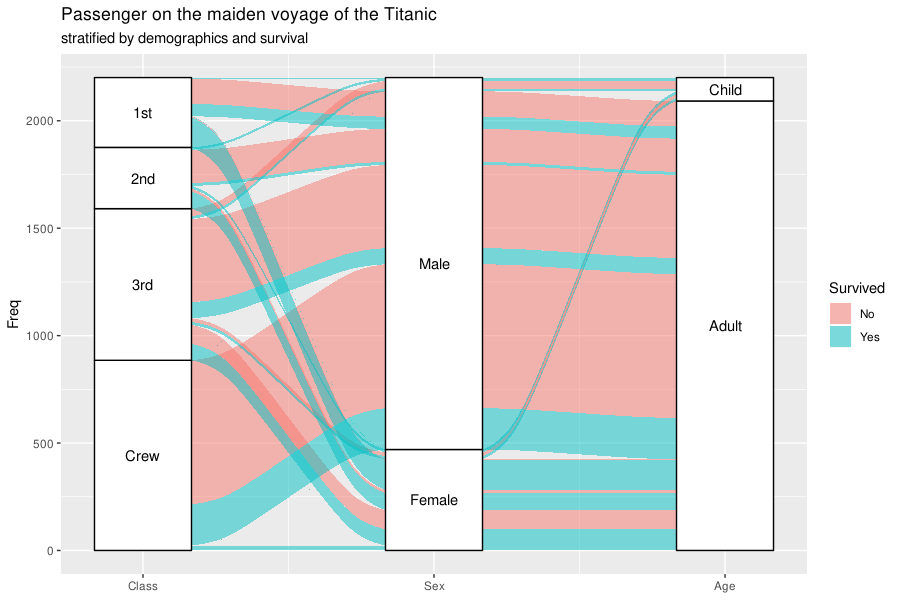
geom_alluvium
最近看文献看到一种新的数据可视化图,Alluvia 图,中文应该是冲积图?不知道。这种图形用来展示分类数据,尤其是多个分类数据以及 Logistic 回归里,美观而且直观,所以决定看一下。
参考主要是 alluvial 和 ggalluvial 的文档 ,有删改。
alluvial 是传统的 Alluvia 图作图包,而 ggalluvial 从名字就能看出来是 ggplot2 包。
主要看 alluvial 的用法,因为它对应 base 作图系统,所以语法简单直接。alluvial 接受的数据形式是宽数据,即整理好的频数表形式。ggalluvial 是 ggplot2 语法系统,自定义程度高,用法丰富。ggalluvial 接受长数据和宽数据两种形式,同时为了保持 tidyverse 语法一致,不支持频数表🙅。后者这里只是简单看一下,用到复杂的数据可视化再去仔细看用法把吧。
主要涉及的数据是耳熟能详的 Titanic:Survived 变量是二分类表示是否幸存,然后是 Class、Sex 和 Age 几个二/多分类变量。由于 alluvial 作图接受宽数据形式,而 Titanic 数据本身是表格数据,
所以还需要首先 as.data.frame() 一下,转成宽数据形式数据框之后就会多出最后一列 Freq 了表示频数的列。数据形式是否符合 alluvial 作图要求也可以直接通过 ggalluvial::is_alluvia_form() 函数来判断。
library("alluvial")
library("dplyr")
library("magrittr")
data("Titanic")
Titanic
## , , Age = Child, Survived = No
##
## Sex
## Class Male Female
## 1st 0 0
## 2nd 0 0
## 3rd 35 17
## Crew 0 0
##
## , , Age = Adult, Survived = No
##
## Sex
## Class Male Female
## 1st 118 4
## 2nd 154 13
## 3rd 387 89
## Crew 670 3
##
## , , Age = Child, Survived = Yes
##
## Sex
## Class Male Female
## 1st 5 1
## 2nd 11 13
## 3rd 13 14
## Crew 0 0
##
## , , Age = Adult, Survived = Yes
##
## Sex
## Class Male Female
## 1st 57 140
## 2nd 14 80
## 3rd 75 76
## Crew 192 20
titan <- as.data.frame(Titanic, stringsAsFactors = FALSE)
titan %>%
head() %>%
knitr::kable()| Class | Sex | Age | Survived | Freq |
|---|---|---|---|---|
| 1st | Male | Child | No | 0 |
| 2nd | Male | Child | No | 0 |
| 3rd | Male | Child | No | 35 |
| Crew | Male | Child | No | 0 |
| 1st | Female | Child | No | 0 |
| 2nd | Female | Child | No | 0 |
ggalluvial::is_alluvia_form(titan)
## [1] TRUEQuick Start with alluvial
首先快速看 alluvial 可视化泰坦尼克数据的例子:
alluvial(titan[,1:4], freq = titan$Freq,
col = ifelse(titan$Survived == "Yes", "darkgreen", "darkgrey"),
border = ifelse(titan$Survived == "Yes", "darkgreen", "darkgrey"),
hide = titan$Freq == 0,
cex = 0.7)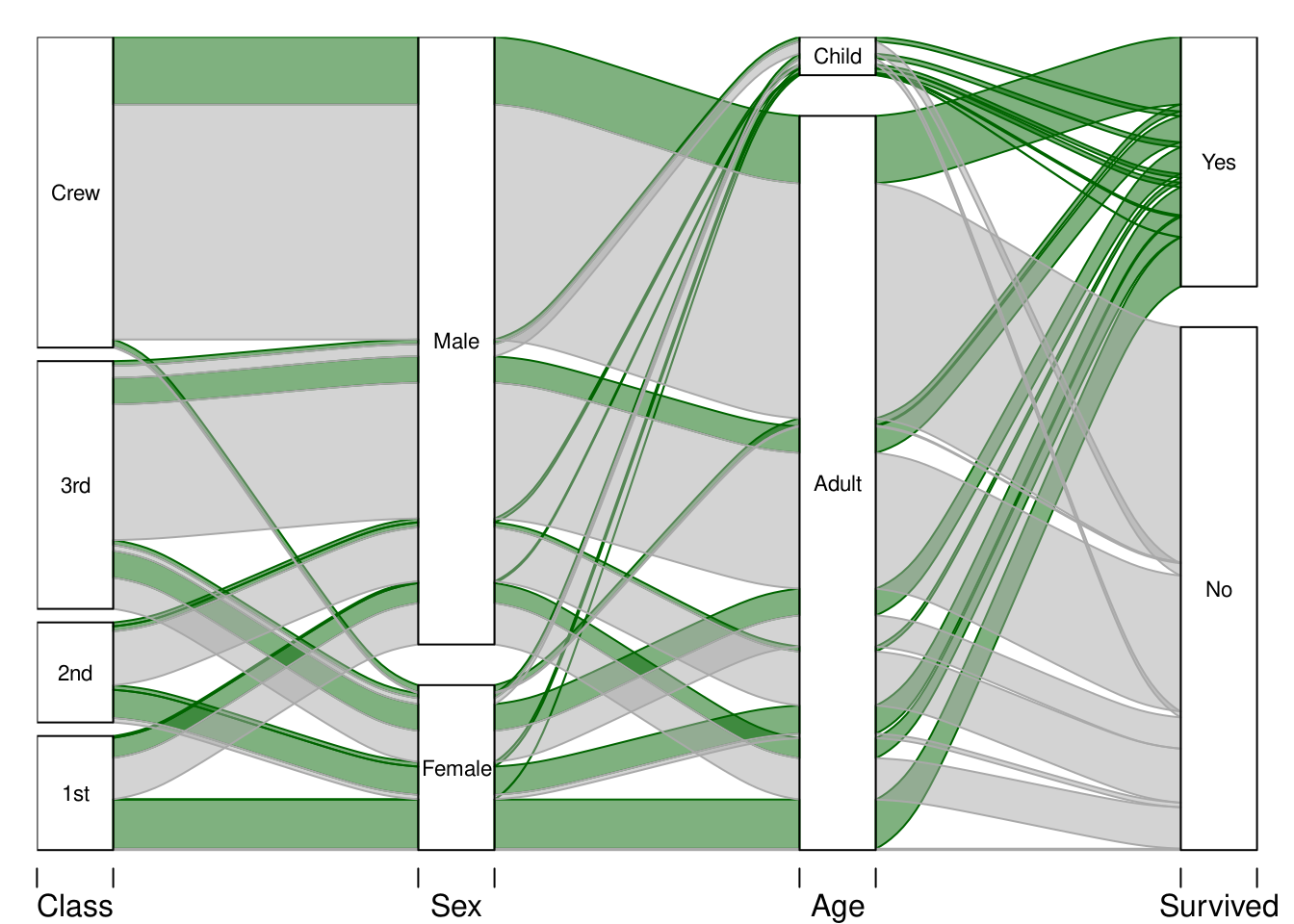
就这张图来简单了解一下 alluvia 图的一些基本特点:
- 横轴是不同的分量变量,自变量和因变量都可以画进来;纵轴是对应分了变量的不同类别的比例
- 一个变量在纵轴上柱子的高度表示分类的比例大小;从变量里画出的条带的宽度也代表相应部分比例大小
- 条带颜色可以再添加一个维度的信息
知道这些以后,仅从上面的图就可以解读到:
- 船上最多的人是船员,男性远多于女性、成人远多于儿童,以及幸存者远少于遇难者🕯️
- 遇难者大多数来自三等舱和船员,而女性遇难者比例明显低于男性
- 船员绝大多数是男性,并且从船员到一等舱,女性比例越来越高,整体幸存者比例也越来越高
- 绝大多数女性遇难者来自三等舱,而一等舱的女性几乎全都幸存
再看一个时间序列数据的例子:
Refugees %>%
head() %>%
knitr::kable()| country | year | refugees |
|---|---|---|
| Afghanistan | 2003 | 2136043 |
| Burundi | 2003 | 531637 |
| Congo DRC | 2003 | 453465 |
| Iraq | 2003 | 368580 |
| Myanmar | 2003 | 151384 |
| Palestine | 2003 | 350568 |
set.seed(39) # for nice colours
cols <- hsv(h = sample(1:10/10),
s = sample(3:12)/15,
v = sample(3:12)/15)
alluvial_ts(Refugees, wave = .3, ygap = 5,
col = cols, plotdir = 'centred', alpha=.9,
grid = TRUE, grid.lwd = 5, xmargin = 0.2,
lab.cex = .7, axis.cex = .8, leg.cex = .7, leg.col = 'white',
ylab = '', xlab = '', border = NA,
title = "UNHCR-recognised refugees\nTop 10 countries (2003-13)\n")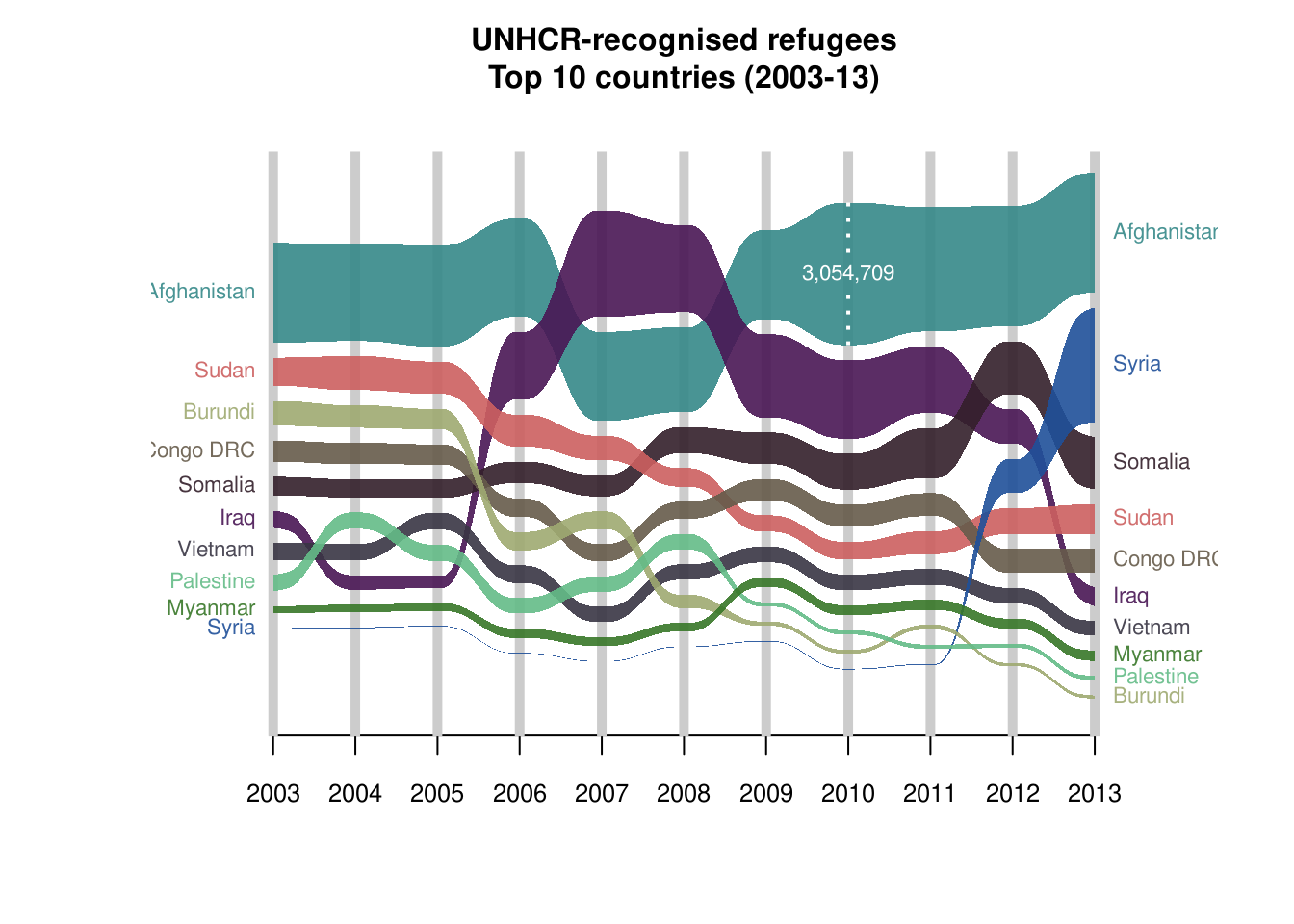
更多用法和自定义
alluvial 简单作图要求提供一个数据框作为数据参数以及一个存放各个分类的频数的向量参数。默认情况下会使用带透明的灰色条带作图。下面是只用 Titanic 数据的 Class 和 Survived 两个变量作图的情况:
# Survival status and Class
titan %>% group_by(Class, Survived) %>%
summarise(n = sum(Freq)) -> tit2d
alluvial(tit2d[,1:2], freq = tit2d$n, blocks = FALSE)
三个变量:
# Survival status, Sex, and Class
titan %>% group_by(Sex, Class, Survived) %>%
summarise(n = sum(Freq)) -> tit3d
alluvial(tit3d[,1:3], freq = tit3d$n, block = TRUE)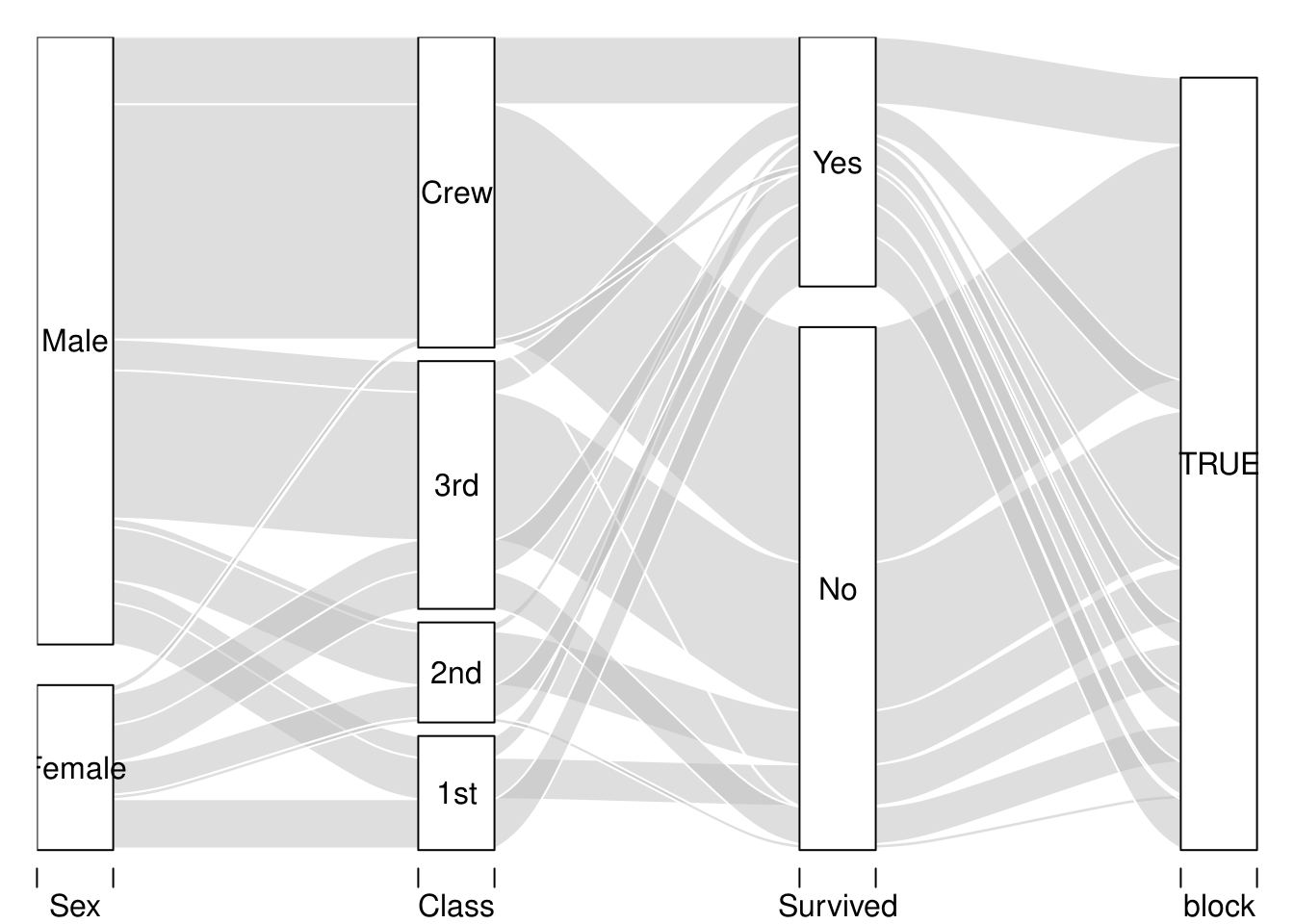
注意 block 参数的作用。
隐藏
hide 参数可以用来隐藏一些条带,比如下面的例子隐藏了所有频数小于 100 的条带
tit3d %>%
dplyr::filter(n < 100)
## # A tibble: 9 x 4
## # Groups: Sex, Class [7]
## Sex Class Survived n
## <chr> <chr> <chr> <dbl>
## 1 Female 1st No 4
## 2 Female 2nd No 13
## 3 Female 2nd Yes 93
## 4 Female 3rd Yes 90
## 5 Female Crew No 3
## 6 Female Crew Yes 20
## 7 Male 1st Yes 62
## 8 Male 2nd Yes 25
## 9 Male 3rd Yes 88
alluvial(tit3d[,1:3], freq=tit3d$n, hide = tit3d$n < 100)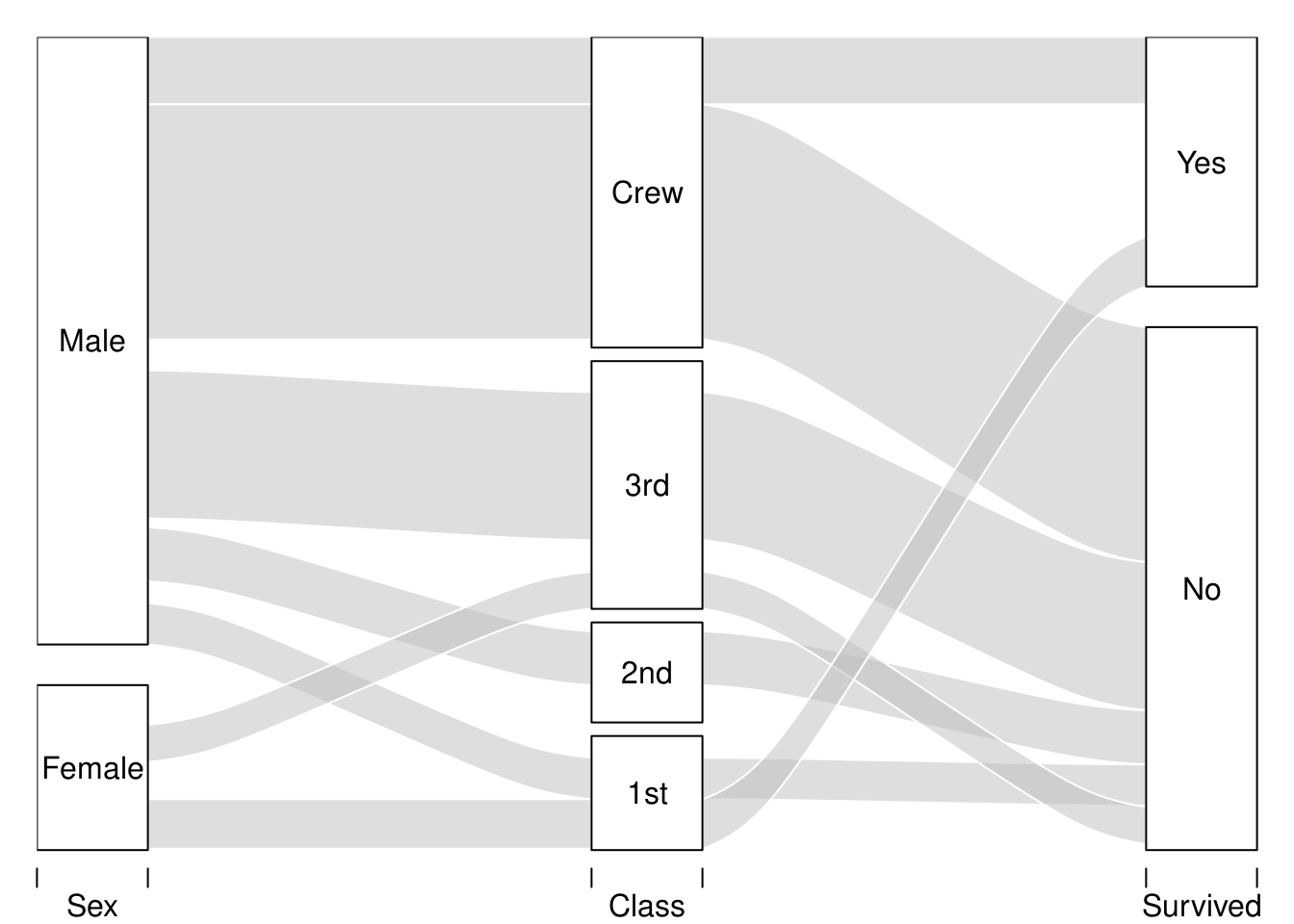
图中就能看到这些少于 100 的条带隐藏之后图中有很多空缺(gap)。要去掉这些 gap 通过 alluvial 包本身无法完成,而需要在作图数据中筛选数据再作图。
改变层次
默认情况下 alluvial 作图时条带的顺序就是提供数据的行的顺序,行在前的在上层(注意画图相当于从下往上画条带,所以第一个条带在图的最前图层,但是位置却在下方)。改变数据里行的顺序就能改变条带的顺序:
d <- data.frame(
x = c(1, 2, 3),
y = c(3 ,2, 1),
freq = c(1, 1, 1)
)
d
## x y freq
## 1 1 3 1
## 2 2 2 1
## 3 3 1 1
alluvial(d[, 1:2],
freq = d$freq,
col = 1:3,
alpha = 1)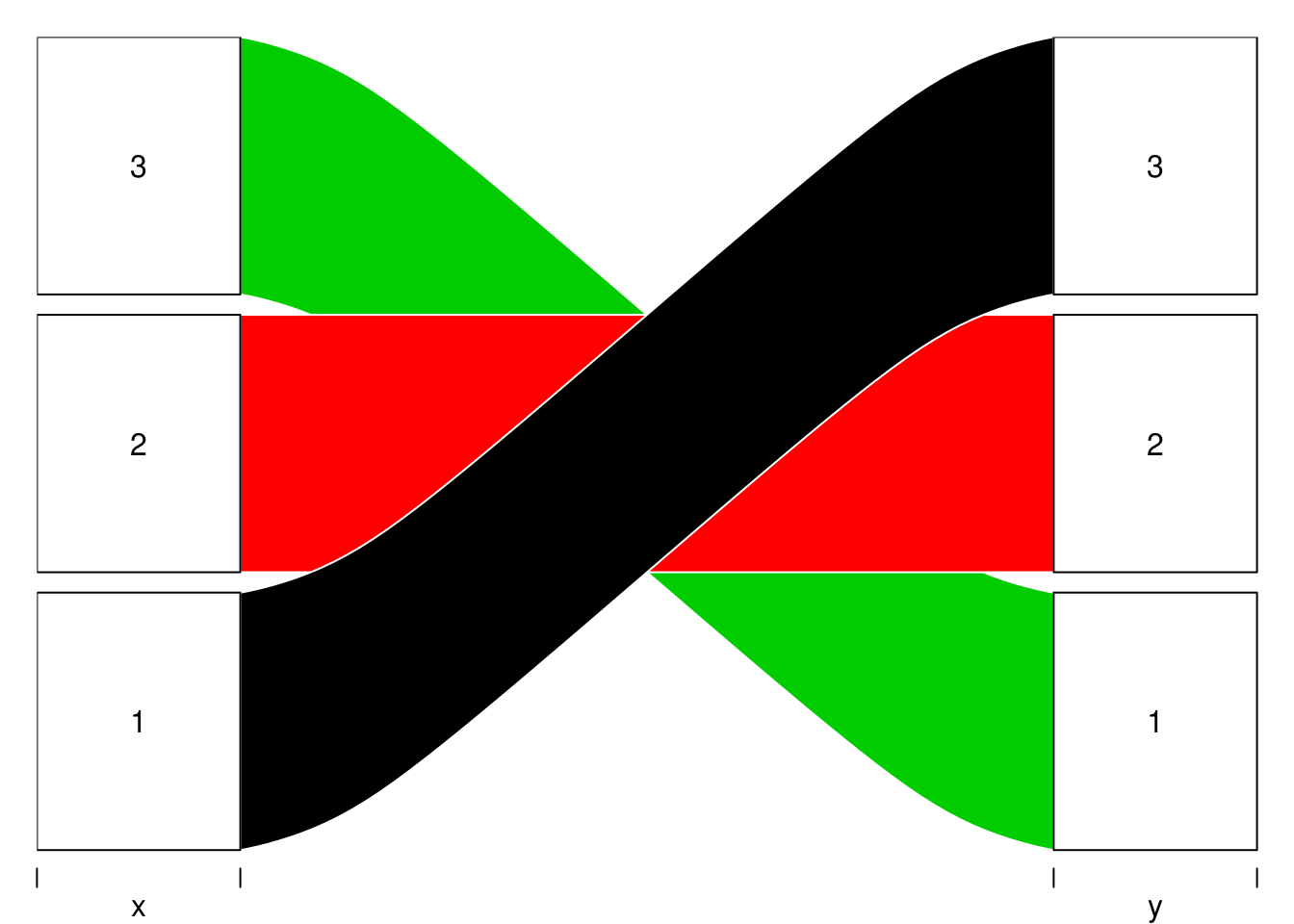
# Reversing the order
alluvial(d[3:1, 1:2],
freq = d$freq,
col = 3:1,
alpha = 1)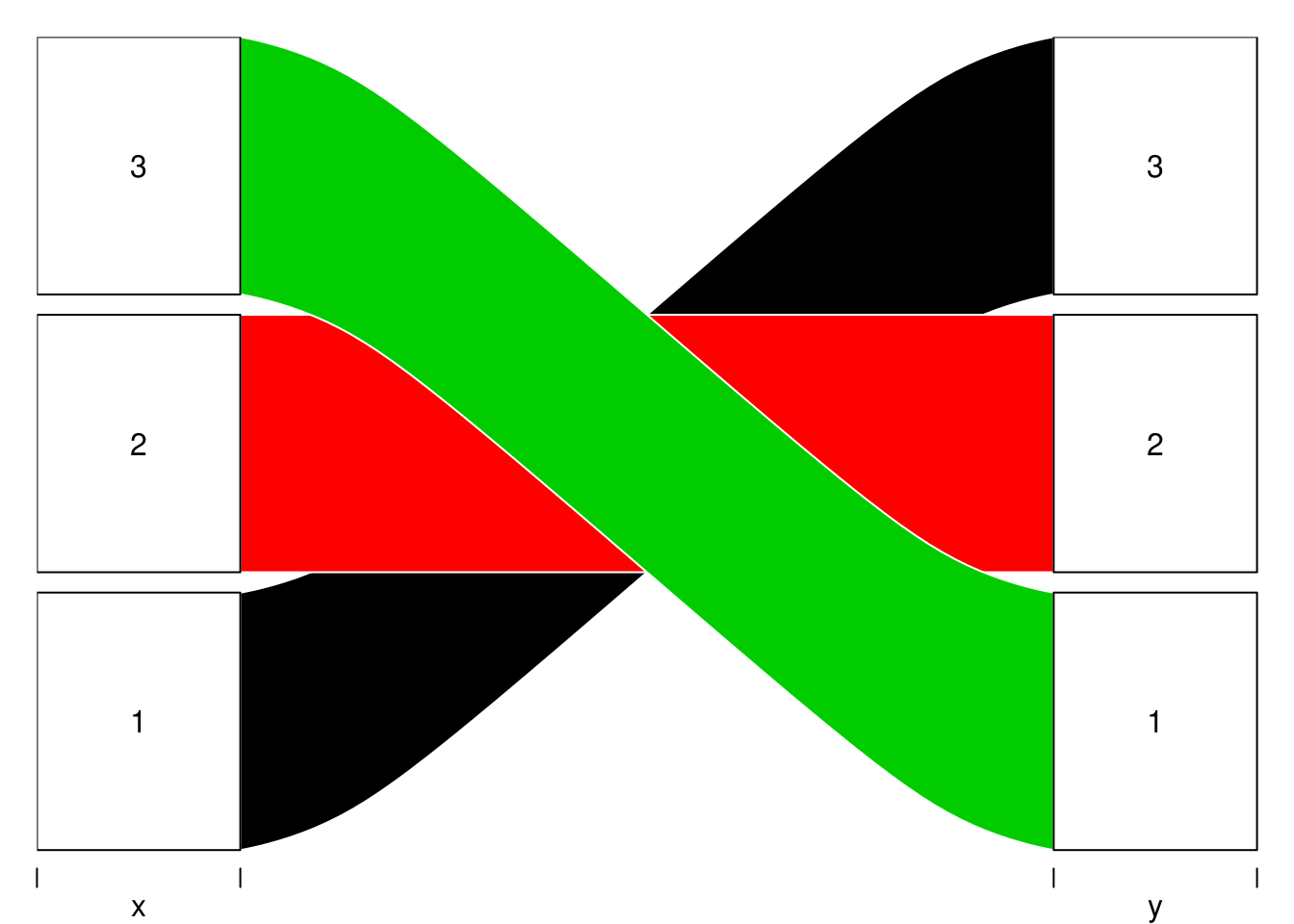
注意后面的代码里指定了颜色并且也是 3:1 反过来的,这是为了对应反过来的行,与之前的图颜色可以保持一致。
通过 layer 参数指定图层顺序可以简单的达到一样的目的:
alluvial(
d[, 1:2],
freq = d$freq,
col = 1:3,
alpha = 1,
layer = 3:1
)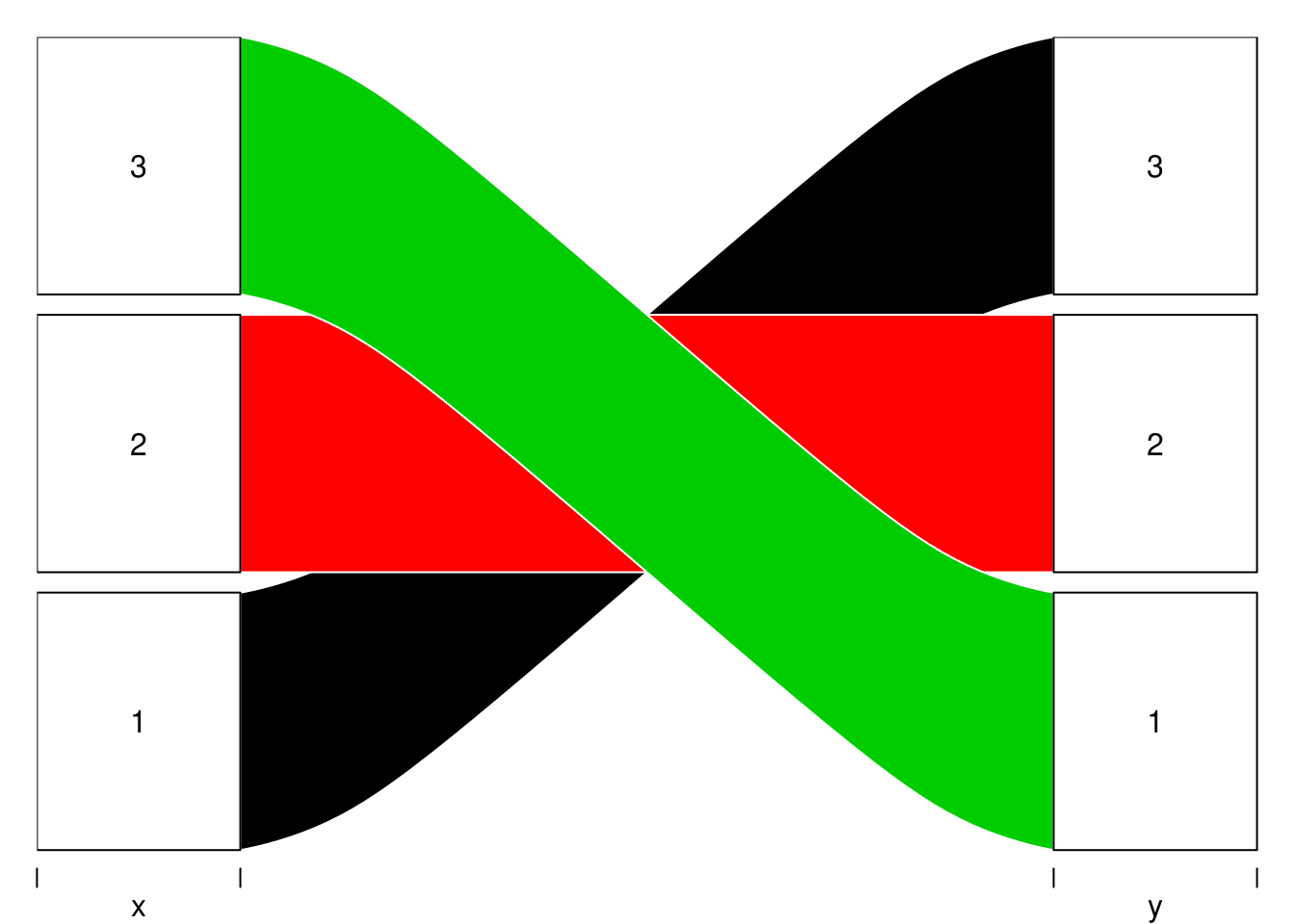
但是通过参数改图层顺序就不需要再手动去调整颜色顺序了。
layer 参数可以接受一个逻辑值,比如有时候只想指定每个特定条带处于最上方。下面的例子里把代表所有幸存者的条带放在最上面:
alluvial(tit3d[,1:3], freq = tit3d$n,
col = ifelse( tit3d$Survived == "Yes", "orange", "grey" ),
alpha = 0.8,
layer = tit3d$Survived == "No"
)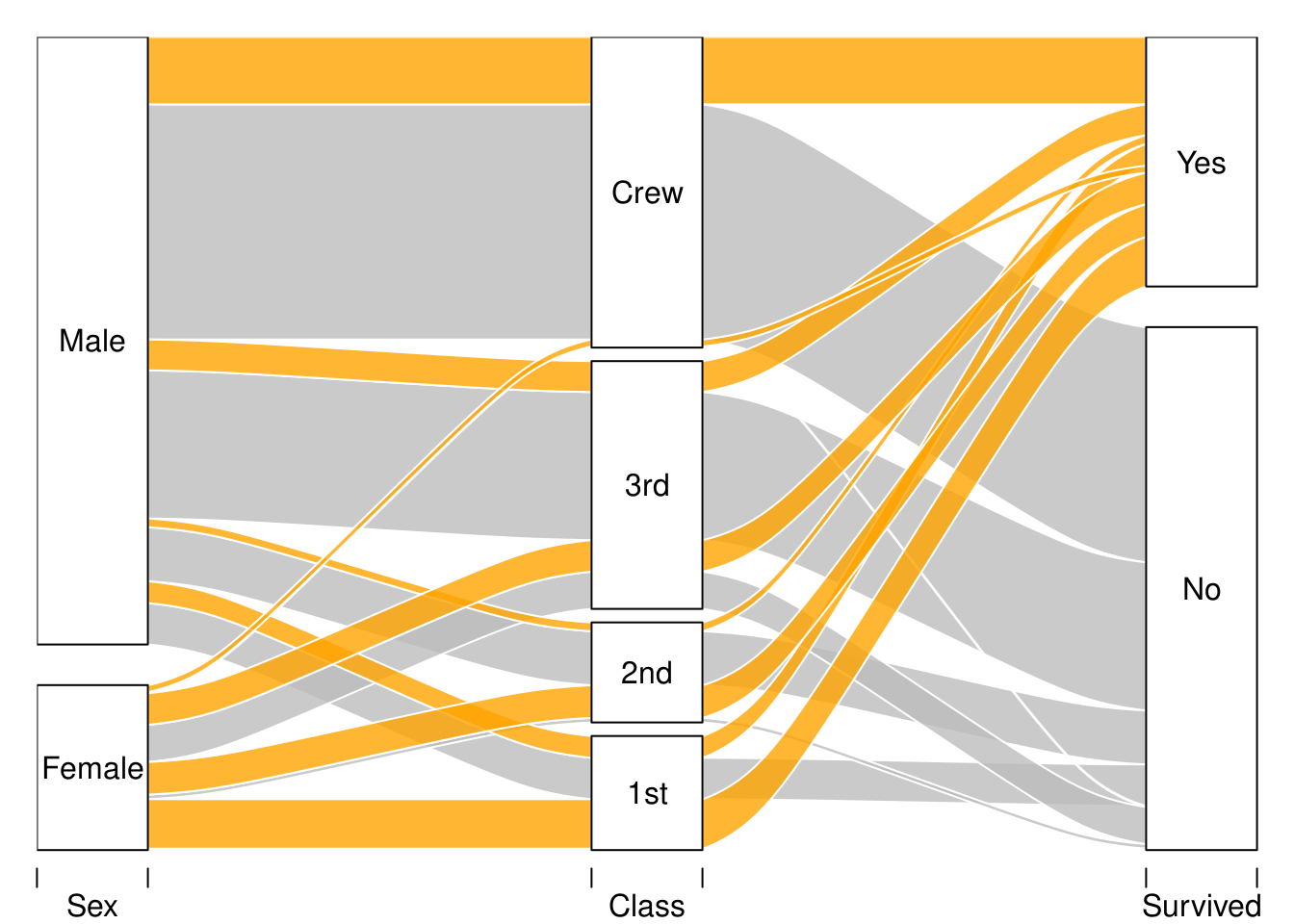
处理逻辑值的时候由 order() 完成,所以事实上是对 TRUE/FALSE 排序,而 TRUE/FALSE 分别是 1/0,所以结果是 FALSE 在前而 TRUE 在后。所以上面画图的结果就是反而 tit3d$Survived == "No" 是在下面。
ggplot2: ggalluvial
首先简单粗暴的看一个例子吧:
library("ggalluvial")
Titanic %>%
as.data.frame() %>%
head() %>%
knitr::kable()| Class | Sex | Age | Survived | Freq |
|---|---|---|---|---|
| 1st | Male | Child | No | 0 |
| 2nd | Male | Child | No | 0 |
| 3rd | Male | Child | No | 35 |
| Crew | Male | Child | No | 0 |
| 1st | Female | Child | No | 0 |
| 2nd | Female | Child | No | 0 |
ggplot(as.data.frame(Titanic),
aes(y = Freq,
axis1 = Survived, axis2 = Sex, axis3 = Class)) +
geom_alluvium(aes(fill = Class),
width = 0, knot.pos = 0, reverse = FALSE) +
guides(fill = FALSE) +
geom_stratum(width = 1/8, reverse = FALSE) +
geom_text(stat = "stratum", label.strata = TRUE, reverse = FALSE) +
scale_x_continuous(breaks = 1:3, labels = c("Survived", "Sex", "Class"))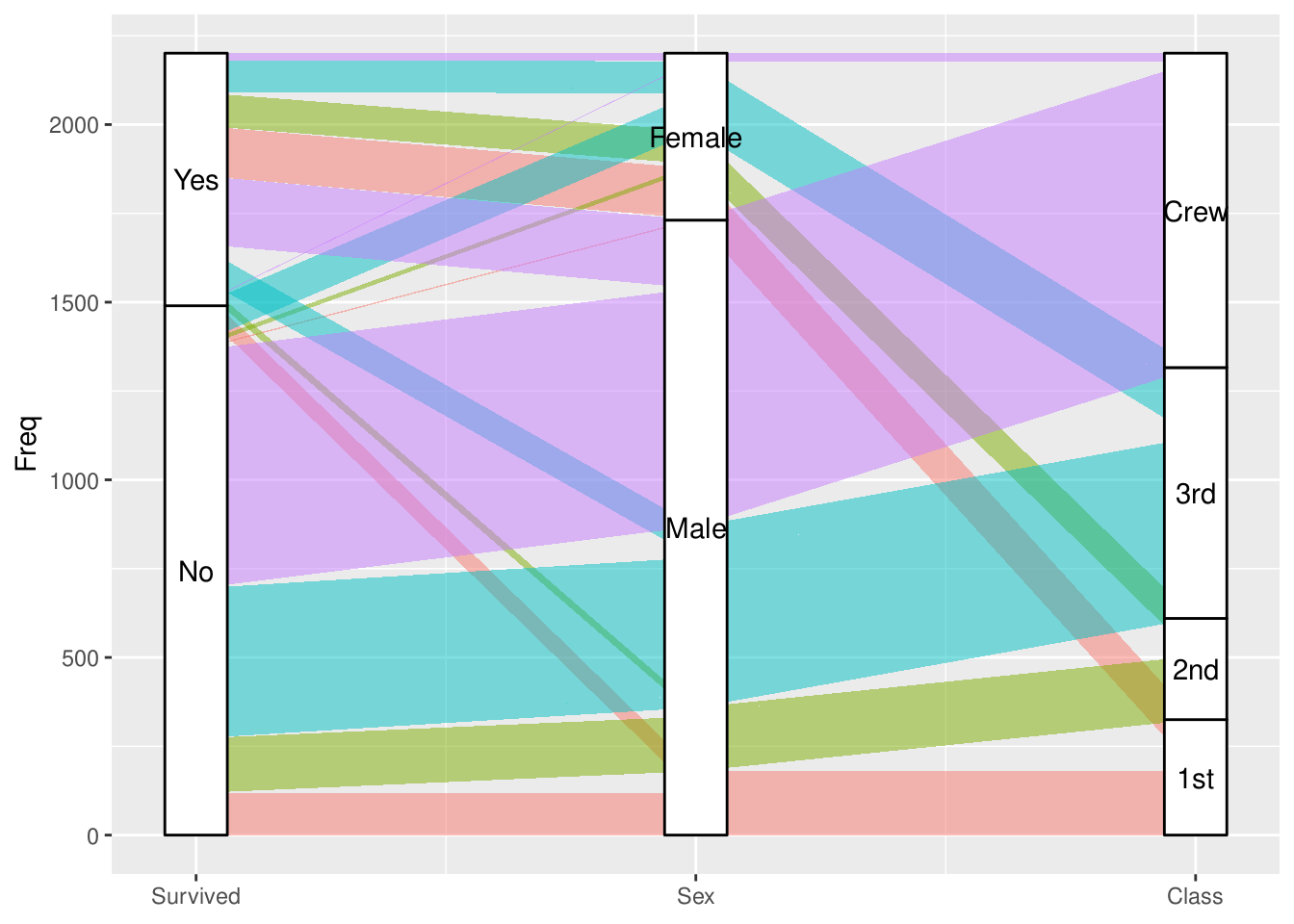
ggalluvial 支持长数据和宽数据格式,但为了保持与 tidyverse 语法的一致性而不支持表格数据格式(而上面用到的 Titanic 和下面会用到的 UCBAdmissions 都是 的原始数据表格数据的)。
宽数据格式
宽数据格式每一行代表由列取值不同的组合所形成的一种人群,然后会有一列单独表示权重(即该人群的频数)。宽数据的每一行对应到冲积图中相当于一个条带。as.data.frame() 默认情况下就会把频数表转换成宽数据形式。
UCBAdmissions 是一个 Berkeley 研究生申请情况的简单数据。Admit 是申请成功还是被拒,Gender 是性别而 Dept 表示部门。来 as.data.frame() 看一下:
is_alluvia_form(as.data.frame(UCBAdmissions), axes = 1:3, silent = TRUE)
## [1] TRUE
UCBAdmissions %>%
as.data.frame() %>%
head() %>%
knitr::kable()| Admit | Gender | Dept | Freq |
|---|---|---|---|
| Admitted | Male | A | 512 |
| Rejected | Male | A | 313 |
| Admitted | Female | A | 89 |
| Rejected | Female | A | 19 |
| Admitted | Male | B | 353 |
| Rejected | Male | B | 207 |
果然,as.data.frame() 会把数据转换成刚刚上面描述的宽数据形式。然后这个数据就可以直接拿来做冲积图了。
ggalluvial 作图语法也是与 alluvial 相一致的:用户需要指定 axis 参数,这一参数会被 stat_alluvium() 和 stat_stratum() 识别处理:
ggplot(as.data.frame(UCBAdmissions),
aes(y = Freq, axis1 = Gender, axis2 = Dept)) +
geom_alluvium(aes(fill = Admit), width = 1/12) +
geom_stratum(width = 1/12, fill = "black", color = "grey") +
geom_label(stat = "stratum", label.strata = TRUE) +
scale_x_discrete(limits = c("Gender", "Dept"), expand = c(.05, .05)) +
scale_fill_brewer(type = "qual", palette = "Set1") +
ggtitle("UC Berkeley admissions and rejections, by sex and department") +
theme_bw()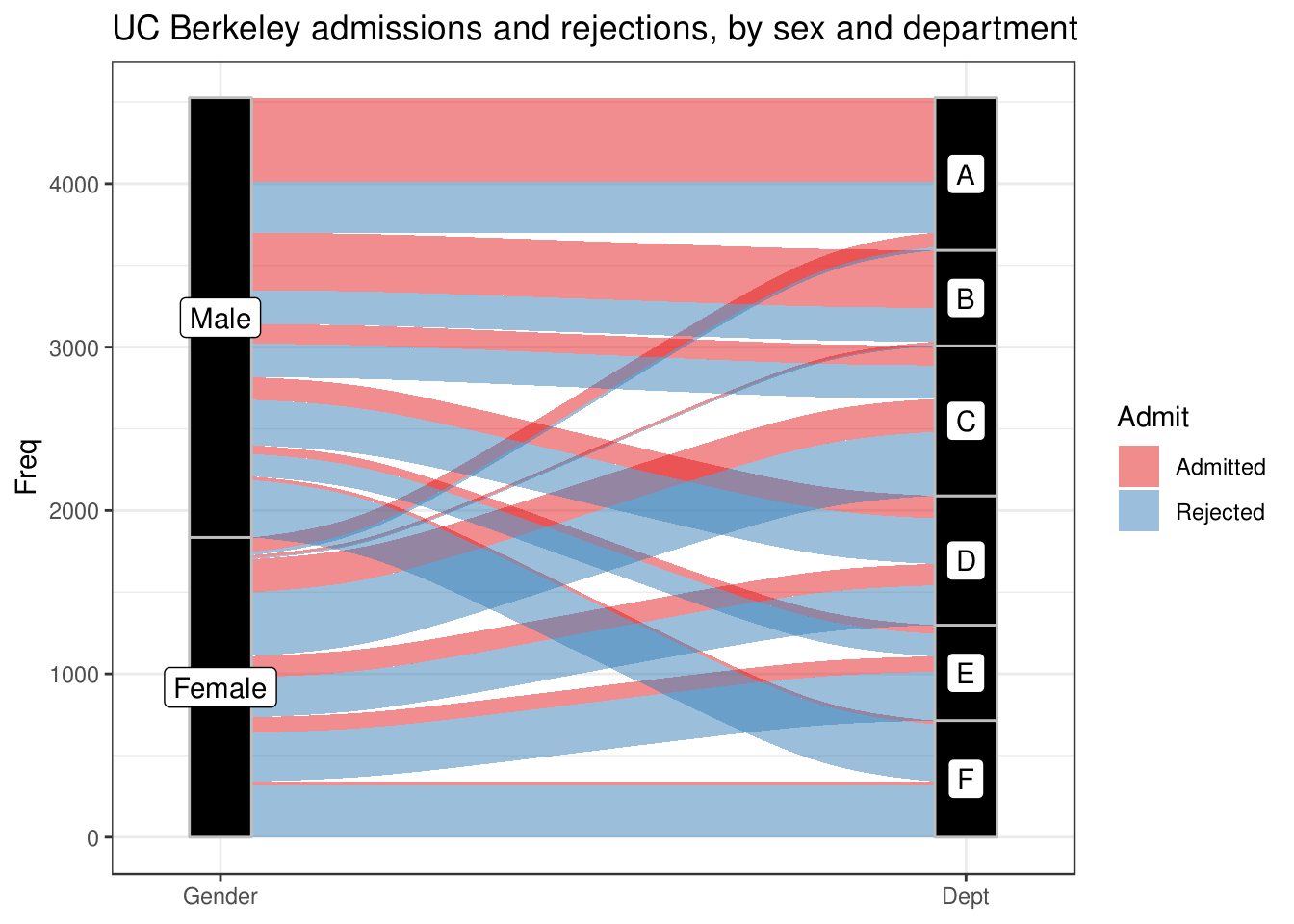
这个作图用到了常用的很多语句,其中最主要的是 geom_alluvium() 和 geom_stratum(),前者画条带,后者画柱子。其他可以一个一个去掉看看图形发生变化来了解每一个参数的作用。
ggalluvial 作出来的图有一个有点就是 Y 轴是有意义的。Y 轴是依据原本数据的尺度而没有做任何转换直接生成的,数据中也没有间隔,所以 Y 轴上画的柱子实际上相当于堆叠起来的柱状图。
长数据格式
ggalluvial 识别的长数据格式是类似于 dyplr 的 gather() 得到的数据那种形式,每一行都代表冲积图中的一个条带。
UCB_lodes <- to_lodes_form(as.data.frame(UCBAdmissions),
axes = 1:3,
id = "Cohort")
head(UCB_lodes, n = 12)
## Freq Cohort x stratum
## 1 512 1 Admit Admitted
## 2 313 2 Admit Rejected
## 3 89 3 Admit Admitted
## 4 19 4 Admit Rejected
## 5 353 5 Admit Admitted
## 6 207 6 Admit Rejected
## 7 17 7 Admit Admitted
## 8 8 8 Admit Rejected
## 9 120 9 Admit Admitted
## 10 205 10 Admit Rejected
## 11 202 11 Admit Admitted
## 12 391 12 Admit Rejected
is_lodes_form(
UCB_lodes,
key = x,
value = stratum,
id = Cohort,
silent = TRUE)
## [1] TRUE还有一个 ggalluvial 能做的是根据数据画 geom_flow() 图。 geom_flow() 图在每一个轴上可以重新设置数据映射关系,用来展示同一数据的变化、重复测量数据会很合适:
data(majors)
majors$curriculum <- as.factor(majors$curriculum)
head(majors)
## student semester curriculum
## 1 1 CURR1 Painting
## 2 2 CURR1 Painting
## 3 6 CURR1 Sculpure
## 4 8 CURR1 Painting
## 5 9 CURR1 Sculpure
## 6 10 CURR1 Painting
ggplot(majors,
aes(x = semester,
stratum = curriculum,
alluvium = student,
fill = curriculum,
label = curriculum)) +
scale_fill_brewer(type = "qual",
palette = "Set2") +
geom_flow(stat = "alluvium",
lode.guidance = "frontback",
color = "darkgray") +
geom_stratum() +
theme(legend.position = "bottom") +
theme_minimal() +
# title("student curricula across several semesters") +
NULL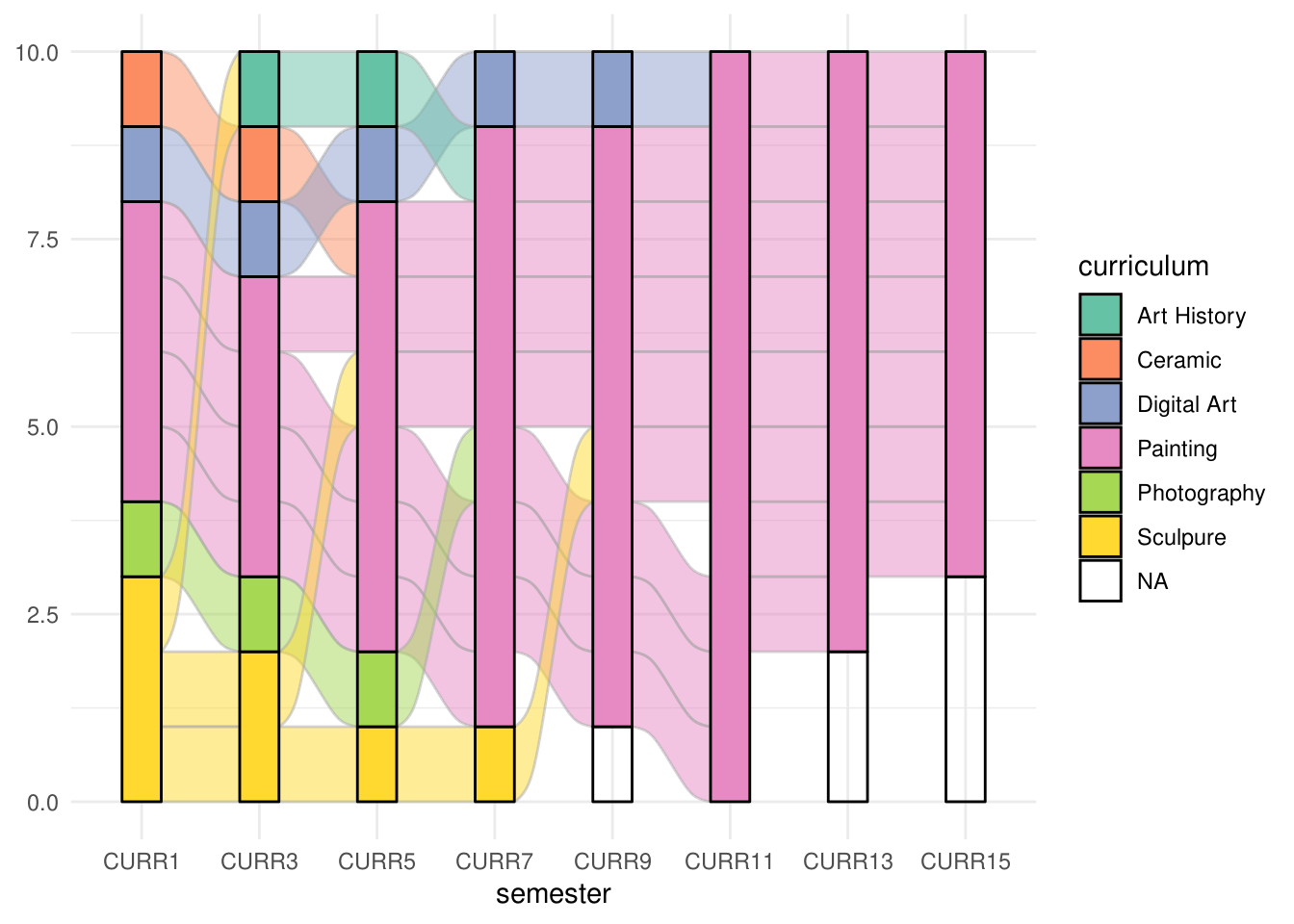
这张图同时还展示了 NA 的一种处理办法,还可以设置参数 na.rm = TRUE。缺失值的处理和 strata 变量是字符型还是因子或数值型的数据类型有关。
长数据形式还允许在相邻轴之间进行合并,这对于查看数据在相邻的两个轴之间的变化很便利:
data(vaccinations)
head(vaccinations)
## freq a subject survey response
## 1 48 0.050367261 1 ms153_NSA Always
## 2 9 0.009443861 2 ms153_NSA Always
## 3 66 0.069254984 3 ms153_NSA Always
## 4 1 0.001049318 4 ms153_NSA Always
## 5 11 0.011542497 5 ms153_NSA Always
## 6 1 0.001049318 6 ms153_NSA Always
levels(vaccinations$response) <- rev(levels(vaccinations$response))
ggplot(vaccinations,
aes(x = survey, stratum = response, alluvium = subject,
y = freq,
fill = response, label = response)) +
scale_x_discrete(expand = c(.1, .1)) +
geom_flow() +
geom_stratum(alpha = .5) +
geom_text(stat = "stratum", size = 3) +
theme(legend.position = "none") +
ggtitle("vaccination survey responses at three points in time")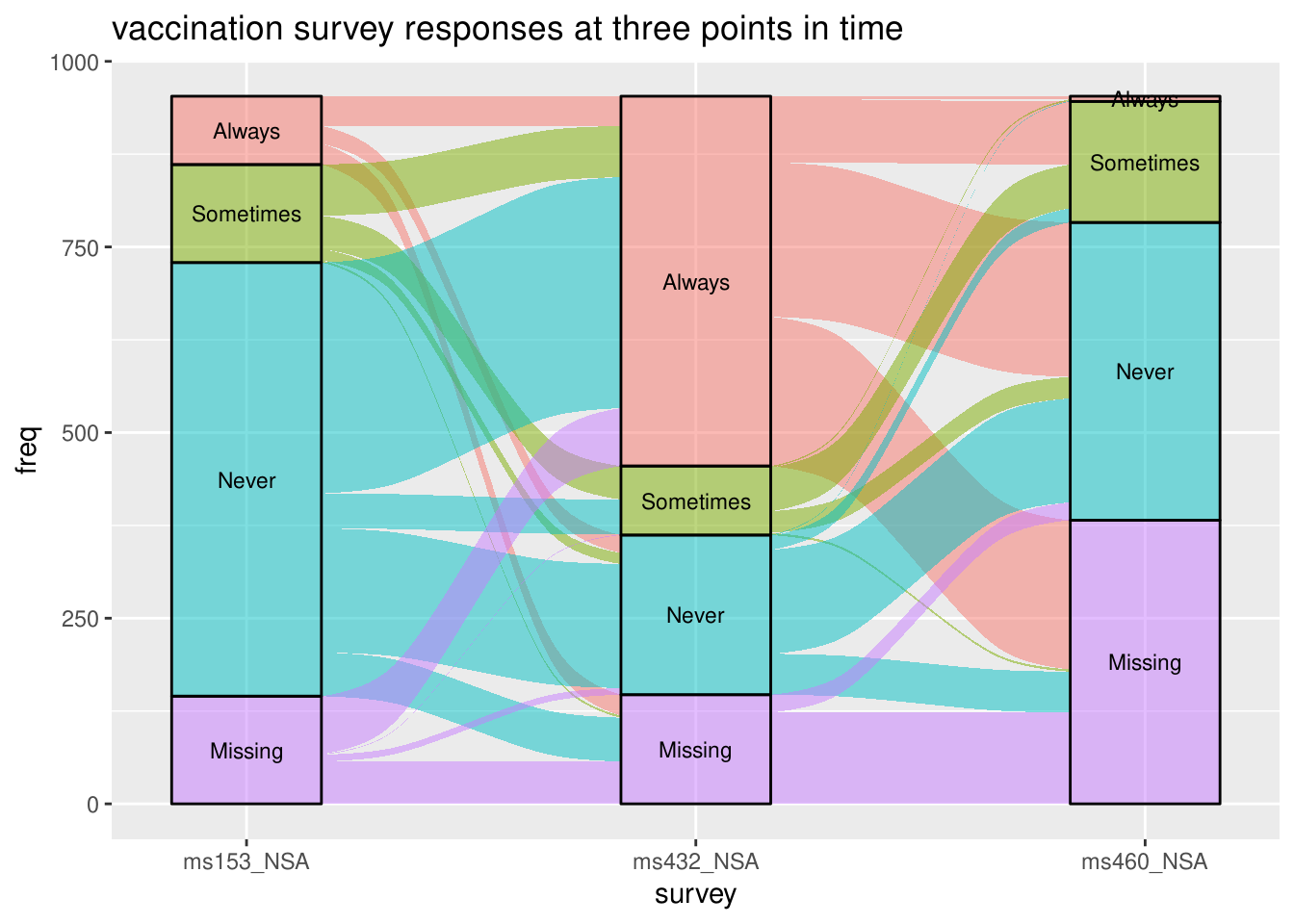
嗯,就这些。ggalluvial 能做 flow 图是一个优势。
文章作者 Jackie
上次更新 2019-10-06 (e1a8247)